Einige Methoden der quantitativen Linguistik wurden in Abschnitt 2.3.6 kurz vorgestellt. Hier sollen diese nun auf die vorliegenden Daten angewendet werden. Diese Untersuchungen werden in einem eigenen Abschnitt behandelt, da sie sich auf die Originaldaten der Freitext-Merkmale ,,Gerätebezeichnung`` und ,,Arbeitsbeschreibung`` beziehen - und nicht auf ihre normierten Partner MT-Geräteart / -Untergeräteart und Arbeitsbeschreibung.
|
|
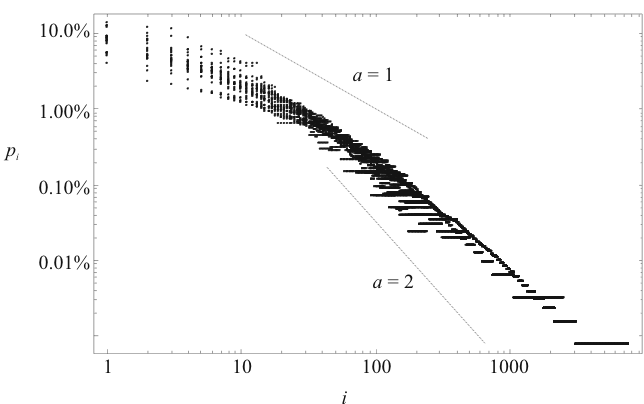
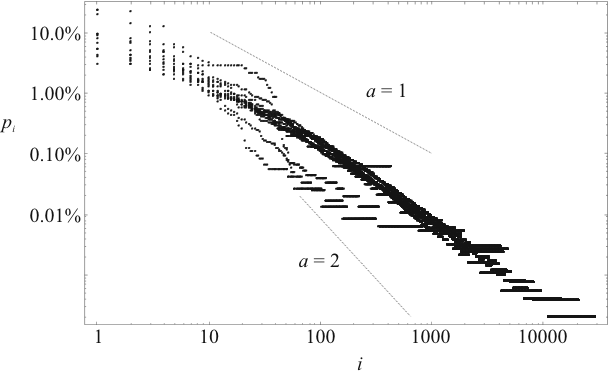
In den Abbildungen 4.67 und 4.68
sind die relativen Worthäufigkeiten ![]() logarithmiert über den
zugehörigen Rängen
logarithmiert über den
zugehörigen Rängen ![]() der nach Häufigkeit absteigend sortierten
Worten logarithmisch für verschiedene Krankenhäuser aufgetragen.
In Abbildung 4.67 sind Worte der originalen
Gerätebezeichnung und in Abbildung 4.67 die Worte
der originalen Arbeitsbeschreibungen dargestellt. Nach dem in
Abschnitt 2.3.6 vorgestellten
Zipf'schen Gesetz sollte sich in dieser Darstellungsart eine
Gerade ergeben. Man erkennt, das für niedrige Ränge sich
der nach Häufigkeit absteigend sortierten
Worten logarithmisch für verschiedene Krankenhäuser aufgetragen.
In Abbildung 4.67 sind Worte der originalen
Gerätebezeichnung und in Abbildung 4.67 die Worte
der originalen Arbeitsbeschreibungen dargestellt. Nach dem in
Abschnitt 2.3.6 vorgestellten
Zipf'schen Gesetz sollte sich in dieser Darstellungsart eine
Gerade ergeben. Man erkennt, das für niedrige Ränge sich
![]() (siehe Formel 2.26) ergibt. Für größere
Ränge scheint
(siehe Formel 2.26) ergibt. Für größere
Ränge scheint ![]() größer zu sein. In [17] wird für große
(mehr als 5000 bis 10 000 Worte) Texte ein ähnliches Verhalten
beobachtet. Es wird vermutet, dass die beiden unterschiedlichen
Exponenten auf zwei verschiedene Wortschätze
hindeuten: einen allgemeinen Wortschatz (
größer zu sein. In [17] wird für große
(mehr als 5000 bis 10 000 Worte) Texte ein ähnliches Verhalten
beobachtet. Es wird vermutet, dass die beiden unterschiedlichen
Exponenten auf zwei verschiedene Wortschätze
hindeuten: einen allgemeinen Wortschatz (
![]() ) und einen
speziellen Wortschatz (
) und einen
speziellen Wortschatz (
![]() ). Für Gerätebezeichnungen
kann man so auf einen allgemeinen Wortschatz von ca. 100 Worten
schließen. Für Arbeitsbeschreibungen ist ein Übergang nur schwach
ausgeprägt und liegt etwa im Bereich von 500 bis 1000 Worten.
). Für Gerätebezeichnungen
kann man so auf einen allgemeinen Wortschatz von ca. 100 Worten
schließen. Für Arbeitsbeschreibungen ist ein Übergang nur schwach
ausgeprägt und liegt etwa im Bereich von 500 bis 1000 Worten.
|
Neben Prüfung der absoluten Worthäufigkeiten ![]() bzw. der
relativen Worthäufigkeiten
bzw. der
relativen Worthäufigkeiten ![]() aus dem letzten Abschnitt auf
Zipf-Verteilung kann auch die zugehörige Wortentropie nach
Abschnitt 4.7.2 berechnet werden.
aus dem letzten Abschnitt auf
Zipf-Verteilung kann auch die zugehörige Wortentropie nach
Abschnitt 4.7.2 berechnet werden.
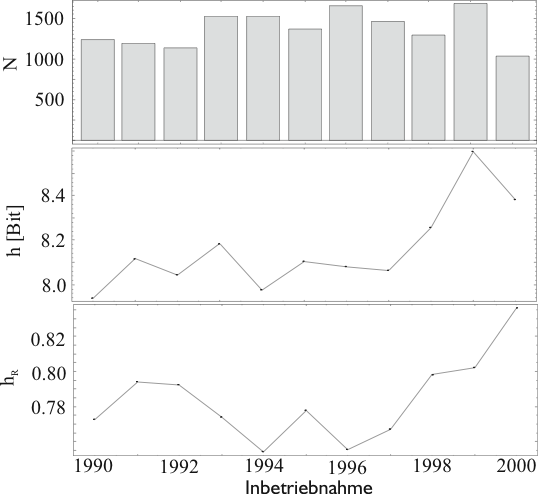
In Abbildung 4.69 sind neben der Wortentropie ![]() die relative Wortentropie
die relative Wortentropie ![]() und die Anzahl
und die Anzahl ![]() der
unterschiedlichen Worte der Gerätebezeichnungen in Abhängigkeit
der Inbetriebnahme aufgetragen. Man erkennt, dass die
Anzahl der unterschiedlichen Worte keinen Trend bezüglich der
Inbetriebnahme besitzt - also etwa konstant bleibt. Die
Wortentropie nimmt jedoch ab 1997 deutlich von 8 auf 8.5 Bit
zu. Dies bedeutet, dass im Mittel pro Wort der
Gerätebezeichnung zwischen
der
unterschiedlichen Worte der Gerätebezeichnungen in Abhängigkeit
der Inbetriebnahme aufgetragen. Man erkennt, dass die
Anzahl der unterschiedlichen Worte keinen Trend bezüglich der
Inbetriebnahme besitzt - also etwa konstant bleibt. Die
Wortentropie nimmt jedoch ab 1997 deutlich von 8 auf 8.5 Bit
zu. Dies bedeutet, dass im Mittel pro Wort der
Gerätebezeichnung zwischen ![]() bzw.
bzw.
![]() verschiedenen ,,Gerätearten`` unterschieden wird.
verschiedenen ,,Gerätearten`` unterschieden wird.
Eine Zunahme der Wortentropie kann zwei Ursachen haben: zum einen
kann die Anzahl der unterschiedlichen Worte ![]() wachsen und damit
auch die Menge der pro Wort übertragenen Information. Es gibt
aber auch noch eine andere Möglichkeit, die jedoch etwas
schwieriger zu verstehen ist. Angenommen man führt ein neues Wort
ein, so nimmt zwar die Information pro Wort zu, jedoch hängt die
Zunahme an Information von der Häufigkeit des neuen Wortes ab.
Verwendet man das neue Wort z.B. nur einmal, so nimmt der
Informationsgehalt der anderen Worte nur minimal zu. Die maximale
Information pro Wort wird dann übertragen, wenn die Häufigkeiten
der verschiedenen Worte gleich hoch sind - die Entropie wird
also bei Gleichverteilung maximal.
wachsen und damit
auch die Menge der pro Wort übertragenen Information. Es gibt
aber auch noch eine andere Möglichkeit, die jedoch etwas
schwieriger zu verstehen ist. Angenommen man führt ein neues Wort
ein, so nimmt zwar die Information pro Wort zu, jedoch hängt die
Zunahme an Information von der Häufigkeit des neuen Wortes ab.
Verwendet man das neue Wort z.B. nur einmal, so nimmt der
Informationsgehalt der anderen Worte nur minimal zu. Die maximale
Information pro Wort wird dann übertragen, wenn die Häufigkeiten
der verschiedenen Worte gleich hoch sind - die Entropie wird
also bei Gleichverteilung maximal.
Damit kann also die Wortentropie auch dadurch zunehmen, dass die
Verteilung der Worthäufigkeiten sich in Richtung Gleichverteilung
ändert. Als Maß für die Gleichverteilung kann die relative
Wortentropie ![]() herangezogen werden, da sie unabhängig von
verschiedenen
herangezogen werden, da sie unabhängig von
verschiedenen ![]() bei Gleichverteilung den Wert 1 annimmt.
bei Gleichverteilung den Wert 1 annimmt.
In Abbildung 4.69 ist zu erkennen, dass die
Gleichverteilung der Worte zunimmt. Man kann also schließen, dass
die Zunahme der Entropie ![]() nicht durch die Zunahme des
Wortschatzes
nicht durch die Zunahme des
Wortschatzes ![]() entstanden ist, sondern durch die Zunahme der
Gleichverteilung
entstanden ist, sondern durch die Zunahme der
Gleichverteilung ![]() .
.
Eine Zunahme der Gleichverteilung ist aber auf eine Abnahme von vielen seltenen Worten zugunsten von wenigen häufigen Worten zurückzuführen. Diese Entwicklung ist zu begrüßen, denn es sind die vielen seltenen Worte, die eine Analyse von Datenbeständen sehr erschweren können. Qualitativ ist also die Entwicklung der Gerätebezeichnungen auf einem guten Weg. Ob diese Entwicklung aber quantitativ ausreicht, kann mit diesen Methoden nicht entschieden werden. Für diese Arbeit war die Normierung der Gerätebezeichnungen noch nicht ausreichend.
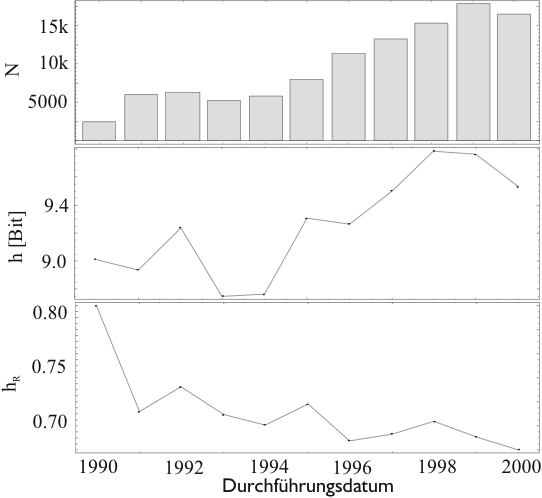
In Abbildung 4.70 sind neben der Wortentropie ![]() die relative Wortentropie
die relative Wortentropie ![]() und die Anzahl der
unterschiedlichen Worte der Arbeitsbeschreibungen in Abhängigkeit
des Durchführungszeitpunkt aufgetragen. Es können die
selben Überlegungen wie bei Abbildung 4.69
angestellt werden. Das bedeutet, dass die Zunahme der Entropie
und die Anzahl der
unterschiedlichen Worte der Arbeitsbeschreibungen in Abhängigkeit
des Durchführungszeitpunkt aufgetragen. Es können die
selben Überlegungen wie bei Abbildung 4.69
angestellt werden. Das bedeutet, dass die Zunahme der Entropie ![]() hauptsächlich auf einer Zunahme des Wortschatzes
hauptsächlich auf einer Zunahme des Wortschatzes ![]() beruht -
mehr noch: es ist sogar eine leichte Abnahme der Gleichverteilung
beruht -
mehr noch: es ist sogar eine leichte Abnahme der Gleichverteilung
![]() zu beobachten. Das bedeutet, dass mit den neuen Worten auch
viele sehr selten verwendete Worte eingeführt werden, die eine
Analyse der Daten erschweren. Die Arbeitsbeschreibungen sind damit
auf einem nicht so guten Weg wie die Gerätebezeichnungen.
zu beobachten. Das bedeutet, dass mit den neuen Worten auch
viele sehr selten verwendete Worte eingeführt werden, die eine
Analyse der Daten erschweren. Die Arbeitsbeschreibungen sind damit
auf einem nicht so guten Weg wie die Gerätebezeichnungen.
|
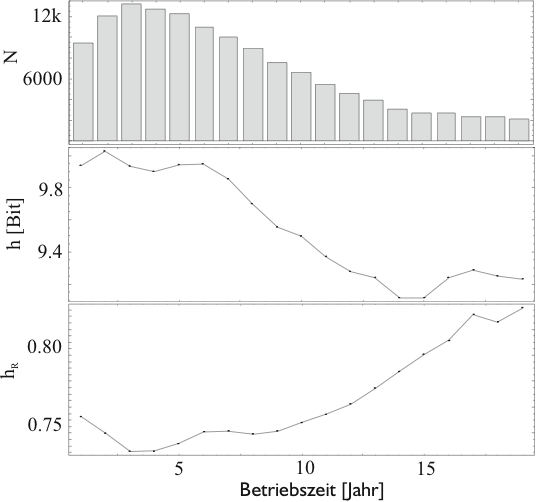
In Abbildung 4.71 sind neben der Wortentropie ![]() die relative Wortentropie
die relative Wortentropie ![]() und die Anzahl der
unterschiedlichen Worte der Arbeitsbeschreibungen in Abhängigkeit
der Betriebszeit aufgetragen. Man erkennt, dass der
Wortschatz
und die Anzahl der
unterschiedlichen Worte der Arbeitsbeschreibungen in Abhängigkeit
der Betriebszeit aufgetragen. Man erkennt, dass der
Wortschatz ![]() für ältere Geräte abnimmt und damit auch der
Informationsgehalt
für ältere Geräte abnimmt und damit auch der
Informationsgehalt ![]() pro Wort. Jedoch erkennt man gleichzeitig
eine Zunahme der Gleichverteilung
pro Wort. Jedoch erkennt man gleichzeitig
eine Zunahme der Gleichverteilung ![]() . Daraus kann man folgern,
dass junge Geräte zwar viele verschiedene Ausfälle zeigen, diese
jedoch recht ungleich verteilt sind - d.h. es gibt wenig häufige
und viele seltene - man darf also eine gewisse Regularität der
unterstellen. Mit zunehmendem Alter nimmt zwar die Anzahl der
möglichen Ausfälle ab, aber die Gleichverteilung nimmt zu - d.h.
wenige häufige Ausfälle nehmen zugunsten von vielen seltenen
Ausfällen ab - die Zufälligkeit der auftretenden Fehler nimmt zu.
. Daraus kann man folgern,
dass junge Geräte zwar viele verschiedene Ausfälle zeigen, diese
jedoch recht ungleich verteilt sind - d.h. es gibt wenig häufige
und viele seltene - man darf also eine gewisse Regularität der
unterstellen. Mit zunehmendem Alter nimmt zwar die Anzahl der
möglichen Ausfälle ab, aber die Gleichverteilung nimmt zu - d.h.
wenige häufige Ausfälle nehmen zugunsten von vielen seltenen
Ausfällen ab - die Zufälligkeit der auftretenden Fehler nimmt zu.
|