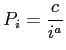In diesem Abschnitt werden kurz die Methoden der Statistik vorgestellt, die in dieser Arbeit verwendet werden. Spezielle Anwendungen der Statistik im Bereich der Instandhaltung von Geräten werden im Abschnitt 2.4.3 vorgestellt.
Es gibt Ereignisse, die nicht vorhersagbar und daher zufällig sind: z.B. das Erhalten einer ungerade Augenzahl nach einem Würfelwurf oder der Ausfall mindestens einer Glühlampe in einer leuchtenden Lichterkette in einer bestimmten Zeitspanne. Beiden Beispielen ist gemeinsam, dass man
Kann man jetzt noch das Zufallsexperiment
beliebig oft durchführen, so kann man
nun zu jedem Ergebnis, das ab jetzt als Ereignis ![]() bezeichnet
wird, die Wahrscheinlichkeit
bezeichnet
wird, die Wahrscheinlichkeit ![]() einführen, mit der das Ereignis
einführen, mit der das Ereignis ![]() eintritt. Wir schreiben:
eintritt. Wir schreiben:
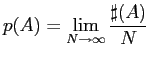 |
(1) |
Dabei bedeutet ![]() die Anzahl der Experimente
mit Ergebnis
die Anzahl der Experimente
mit Ergebnis ![]() und
und ![]() die Gesamtzahl der durchgeführten
Experimente.
die Gesamtzahl der durchgeführten
Experimente.
In der Praxis muss man sich oft mit Näherungen bzw. Schätzwerten
der Wahrscheinlichkeit ![]() begnügen, da man
Experimente nicht beliebig häufig wiederholen kann. Nach dem
schwachen Gesetz der großen Zahl
(z.B. [3] Seite 129) wird
begnügen, da man
Experimente nicht beliebig häufig wiederholen kann. Nach dem
schwachen Gesetz der großen Zahl
(z.B. [3] Seite 129) wird ![]() aber mit steigender
Zahl an Experimenten beliebig genau approximiert. Aus der obigen
Definition folgt, dass
aber mit steigender
Zahl an Experimenten beliebig genau approximiert. Aus der obigen
Definition folgt, dass
![]() . Außerdem gilt für
sich ausschließende Ereignisse
. Außerdem gilt für
sich ausschließende Ereignisse ![]() und
und ![]() :
:
| (2) |
Im folgenden wird auch noch der Begriff der ,,Bedingten Wahrscheinlichkeit`` benötigt:
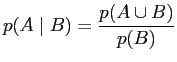 |
(3) |
Dabei gibt dieser Wert die Wahrscheinlichkeit an, dass
das Ereignis ![]() eintritt unter der Voraussetzung, dass das
Ereignis
eintritt unter der Voraussetzung, dass das
Ereignis ![]() eintritt.
eintritt.
|
Neben zufälligen Ereignissen werden in dieser Arbeit auch
zufällige Variable untersucht. Zum Beispiel ist die Zeit zwischen
zwei Ausfällen eines Gerätes eine so genannte Zufallsvariable.
Die Wahrscheinlichkeit, bei einer
Bestimmung der Zufallsvariablen ![]() einen Wert
einen Wert ![]() zu erhalten,
für den
zu erhalten,
für den
![]() gilt, wird als
gilt, wird als
![]() bezeichnet.
bezeichnet.
Als reellwertig wird eine Zufallsvariable bezeichnet, wenn ihre Wertemenge reell ist. Als diskret / stetig wird sie bezeichnet, wenn ihr Definitionsbereich diskret / stetig ist. Alle im folgenden betrachteten Zufallsvariablen sind stetig. Die Zusammenhänge lassen sich aber leicht auf diskrete Zufallsvariablen übertragen.
Zu einer stetigen Zufallsvariablen ![]() lässt sich eine
Verteilungsfunktion
lässt sich eine
Verteilungsfunktion ![]() angeben:
angeben:
| (4) |
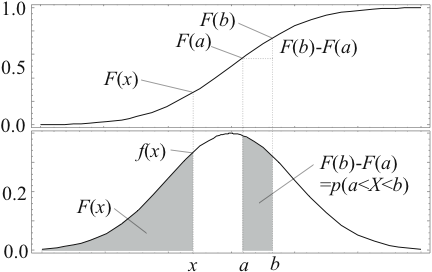
Diese Verteilungsfunktion ist monoton steigend und hat einen Wertebereich von 0 bis 1.
Wenn eine Verteilungsfunktion existiert, so kann man auch eine
Wahrscheinlichkeitsdichte
![]() angeben. Für stetige Zufallsvariablen gilt:
angeben. Für stetige Zufallsvariablen gilt:
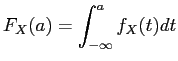 wobei wobei |
(5) |
Mit der Wahrscheinlichkeitsdichte können wir nun schreiben:
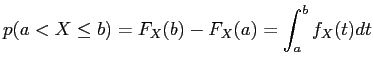 |
(6) |
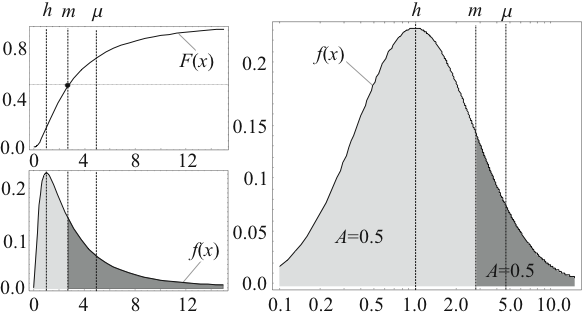
Die Zusammenhänge für stetige Verteilungsfunktionen und Wahrscheinlichkeitsdichten sind in Abbildung 2.1 angegeben.
Seien ![]() mit
mit
![]() eine Gruppe bzw. Stichprobe
von Werten einer diskreten Zufallsvariablen
eine Gruppe bzw. Stichprobe
von Werten einer diskreten Zufallsvariablen ![]() . Die empirische
Verteilungsfunktion
. Die empirische
Verteilungsfunktion
![]() lautet dann (siehe [3] Seite 94)
lautet dann (siehe [3] Seite 94)
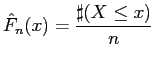 |
(7) |
mit der Anzahl
![]() der Stichprobenwerte
der Stichprobenwerte
![]() sind. Von dieser Funktion wird im
Folgenden noch häufig Gebrauch gemacht.
sind. Von dieser Funktion wird im
Folgenden noch häufig Gebrauch gemacht.
Analog zum Gesetz der großen Zahl
bei der Wahrscheinlichkeit gilt hier der Satz von Glivenko und
Cantelli:
Die Differenz
![]() strebt für große
strebt für große ![]() mit der
Wahrscheinlichkeit 1 gegen Null (siehe [3] Seite 94),
wenn
mit der
Wahrscheinlichkeit 1 gegen Null (siehe [3] Seite 94),
wenn ![]() die Verteilung der Zufallsvariablen
die Verteilung der Zufallsvariablen ![]() ist.
ist.
Zufallsvariablen und deren Verteilungsfunktionen kann man sowohl stetig als auch diskret formulieren, um den mit ihnen verbunden Formalismus auf möglichst viele Anwendungsfälle übertragen zu können. Zufallsvariablen können in drei (ein stetiges und zwei diskrete) verschiedene Gruppen - so genannte Skalenniveaus - eingeteilt werden:
Diese Reihenfolge der Skalenniveaus ist nicht zufällig gewählt. Durch Fortlassen der Eigenschaft einen Abstand bestimmen zu können (Metrik), erhält man im Normalfall aus einer metrischen eine ordinal skalierte Zufallsvariablen. Durch Fortlassen der Ordnung einer ordinalen Zufallsvariablen erhält man eine kategorial skalierte Zufallsvariable.
Man kann die Skalenniveaus also anhand ihrer Eigenschaften anordnen und von höheren und niedrigeren Skalenniveaus sprechen. Die Transformation von höheren zu niedrigeren Skalenniveaus und umgekehrt wird in Abschnitt 3.6 kurz vorgestellt.
Zur groben Charakterisierung von Zufallsvariablen sind Mittel-
bzw. Erwartungswert
und Varianz
bzw. Standardabweichung geeignet. Der
Erwartungswert ![]() einer diskreten Verteilungsfunktion
einer diskreten Verteilungsfunktion ![]() lautet (siehe [3] Seite 95)
lautet (siehe [3] Seite 95)
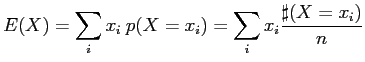 |
(8) |
Die ![]() bezeichnen hier die verschiedenen Werte, die
von der diskreten Zufallsvariablen angenommen werden und die
bezeichnen hier die verschiedenen Werte, die
von der diskreten Zufallsvariablen angenommen werden und die
![]() die zugehörige Anzahl. Für den Erwartungswert
gelten umfangreiche Rechenregeln (z.B. [3] Seiten 95 und
96).
die zugehörige Anzahl. Für den Erwartungswert
gelten umfangreiche Rechenregeln (z.B. [3] Seiten 95 und
96).
Für die Varianz ![]() und die Standardabweichung
und die Standardabweichung ![]() gilt
in diesem Fall (siehe [3] Seite 95):
gilt
in diesem Fall (siehe [3] Seite 95):
![$\displaystyle Var(X) = \sigma^2 = E(X-E(X)) = \sum_i [x_i-E(X)] \: p(X=x_i)$](img78.png) |
(9) |
Hat man die Messwerte
![]() der Zufallsvariablen
der Zufallsvariablen
![]() und die Messwerte
und die Messwerte ![]()
![]() der
Zufallsvariablen
der
Zufallsvariablen ![]() gepaart als
Messpunkte
gepaart als
Messpunkte
![]() zur Verfügung, so besteht oft der Wunsch
bei geeigneter Verteilung der Messpunkte eine Gerade
zur Verfügung, so besteht oft der Wunsch
bei geeigneter Verteilung der Messpunkte eine Gerade
![]() durch diese Messpunkte zu legen, die die Darstellung des
Zusammenhangs möglichst gut an die Messwerte angepasst und in
einfacher Form darstellt. Die einfache Darstellung ist durch die
unkomplizierte Geradengleichung gegeben. Für die optimale
Anpassung dieser Geraden an die Messwerte fordert man folgende
Minimalbedingung (siehe [5] Seiten 1028 und 1029):
durch diese Messpunkte zu legen, die die Darstellung des
Zusammenhangs möglichst gut an die Messwerte angepasst und in
einfacher Form darstellt. Die einfache Darstellung ist durch die
unkomplizierte Geradengleichung gegeben. Für die optimale
Anpassung dieser Geraden an die Messwerte fordert man folgende
Minimalbedingung (siehe [5] Seiten 1028 und 1029):
| (10) |
Damit ergibt sich folgende Regressionsgerade als Lösung:
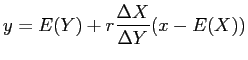 mit mit |
(11) |
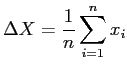 , ,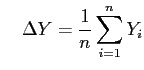 und und |
(12) |
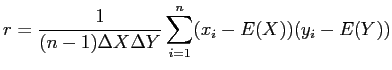 |
(13) |
Oft ist es nicht sinnvoll, den Zusammenhang zweier
Zufallsvariablen ![]() und
und ![]() durch eine Gerade zu beschreiben, da
sich dann die oben geforderte Minimalbedingung nicht gut
befriedigen lässt. In einem solchen Fall kann es hilfreich sein,
eine Regression der Abbildungen
durch eine Gerade zu beschreiben, da
sich dann die oben geforderte Minimalbedingung nicht gut
befriedigen lässt. In einem solchen Fall kann es hilfreich sein,
eine Regression der Abbildungen ![]() und
und ![]() vorzunehmen,
wobei diese Funktionen durch Ausprobieren oder externe
Informationen ergeben.
vorzunehmen,
wobei diese Funktionen durch Ausprobieren oder externe
Informationen ergeben.
Führt auch die Transformation der Messpunkte zu keinem ausreichend linearem Verlauf, oder ist eine Transformation aus anderen Gründen nicht erwünscht, so kann man auf die nichtlineare Regression zurückgreifen. Die in dieser Arbeit vorgenommen nichtlinearen Regressionen wurden mit der Software Mathematica 5.0 vorgenommen.
|
Im Laufe der Arbeit werden einige Regressionen mit der log-Normalverteilung durchgeführt. Um die dabei gewonnenen Ergebnisse besser interpretieren zu können, sei hier die log-Normalverteilung etwas genauer untersucht.
Für Wahrscheinlichkeitsdichte ![]() der log-Normalverteilung gilt
der log-Normalverteilung gilt
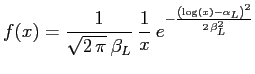 |
(14) |
Dabei wird der Parameter ![]() Häufungspunkt
und den Parameter
Häufungspunkt
und den Parameter ![]() Streuung der
log-Normalverteilung genannt. Die einzigen Unterschiede der
log-Normalverteilung zur Normalverteilung sind der veränderte
Normierungsfaktor und und die Transformation der Argumente durch
die
Streuung der
log-Normalverteilung genannt. Die einzigen Unterschiede der
log-Normalverteilung zur Normalverteilung sind der veränderte
Normierungsfaktor und und die Transformation der Argumente durch
die ![]() -Funktion.
-Funktion.
In Abbildung 2.2 sind die Verteilungsfunktion ![]() und die Wahrscheinlichkeitsdichte
und die Wahrscheinlichkeitsdichte ![]() der log-Normalverteilung
dargestellt. Zusätzlich sind auch Häufungspunkt
der log-Normalverteilung
dargestellt. Zusätzlich sind auch Häufungspunkt ![]() , Median
, Median
![]() und Mittelwert
und Mittelwert ![]() eingezeichnet. Es gelten
eingezeichnet. Es gelten
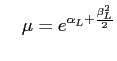 |
(15) |
Durch die Transformation der Argumente fallen Häufungspunkt, Median und Mittelwert der log-Normalverteilung nicht wie bei der Normalverteilung zusammen. In diesem Fall spricht man auch von einer Schiefe (skewness) der Verteilung. Der Mittelwert der log-Normalverteilung hängt also im Gegensatz zur Normalverteilung nicht nur vom Häufungspunkt sondern auch von der Streuung ab.
Durch die Definition der Schiefe ![]() im Anhang
E.1 kann man diese quantifizieren.
Für die log-Normalverteilung ergibt sich damit
im Anhang
E.1 kann man diese quantifizieren.
Für die log-Normalverteilung ergibt sich damit
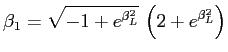 |
(16) |
Da die Schiefe ![]() monoton vom Parameter
monoton vom Parameter ![]() abhängt,
kann man aus Gründen der Einfachheit zum Vergleich der Schiefen
zweier log-Normalverteilungen den Parameter
abhängt,
kann man aus Gründen der Einfachheit zum Vergleich der Schiefen
zweier log-Normalverteilungen den Parameter ![]() heranziehen.
heranziehen.
Im Normalfall sollte eine statistisch testende Analyse folgendermaßen ablaufen:
Das Vorgehen bei dieser Untersuchung unterscheidet sich zwangsläufig stark von dem oben genannten Vorgehen:
Es können also verschiedene Verfahren nur auf die schon erhobenen Daten angewendet und dann entschieden werden, ob die gewonnenen Erkenntnisse von Interesse sind - also eine Umkehrung des normalen Vorgehens. Aufgrund dieser Randbedingungen ist es nicht unkritisch, testende Statistik zu betreiben - man muss also hauptsächlich mit deskriptiver Statistik auskommen.
In einigen Fällen wird jedoch auch in dieser Arbeit testenden
Statistik verwendet. Zur Beurteilung
der Regressionen an eine willkürlich ausgewählte
log-Normalverteilung wird der Kolmogoroff-Smirnow-Test für die
Güte von Anpassungen verwendet. Für die Untersuchung von
Mehrfeldtafeln bzw. Kreuztabellen wird der ![]() -Test und der
Kontingenzkoeffizient von Pawlik verwendet. Korrelationen werden
mit dem Spearmanschen Rang-Korrelationskoeffizienten untersucht.
-Test und der
Kontingenzkoeffizient von Pawlik verwendet. Korrelationen werden
mit dem Spearmanschen Rang-Korrelationskoeffizienten untersucht.
Aus den vorliegenden Daten ![]() , die als Vektor oder auch als
Matrix vorliegen können, wird eine Testgröße
, die als Vektor oder auch als
Matrix vorliegen können, wird eine Testgröße
![]() berechnet. Anhand dieser Testgröße kann man entscheiden,
ob die Nullhypothese
berechnet. Anhand dieser Testgröße kann man entscheiden,
ob die Nullhypothese ![]() angenommen oder
verworfen wird und damit die Alternativhypothese
angenommen oder
verworfen wird und damit die Alternativhypothese
![]() angenommen wird. Testgröße,
Nullhypothese und Alternativhypothese werden durch den gewählten
Test festgelegt.
angenommen wird. Testgröße,
Nullhypothese und Alternativhypothese werden durch den gewählten
Test festgelegt.
Bei der Entscheidung zwischen Null- und Alternativhypothese
anhand der ermittelten Testgröße kann der Test zwei prinzipielle
Fehler machen. Die Nullhypothese kann abgelehnt werden, obwohl sie
richtig ist - diesen Fehler nennt man Fehler 1. Art oder
![]() -Fehler. Wird die Nullhypothese jedoch nicht abgelehnt,
obwohl die Alternativhypothese vorliegt, so spricht man vom
Fehler 2. Art bzw.
-Fehler. Wird die Nullhypothese jedoch nicht abgelehnt,
obwohl die Alternativhypothese vorliegt, so spricht man vom
Fehler 2. Art bzw. ![]() -Fehler.
-Fehler.
Es hat sich eingebürgert, Entscheidungen zwischen Null- und
Alternativhypothese als signifikant zu
bezeichnen, wenn der ![]() -Fehler kleiner als 5% ist. Der
-Fehler kleiner als 5% ist. Der
![]() -Fehler kann durch Wahl des kritischen Wertes
festgelegt werden. Der kritische Wert
ist dabei die Grenze zwischen Werten der Testgröße, die die
Nullhypothese bestätigen bzw. widerlegen. Eine zu starke
Verkleinerung des
-Fehler kann durch Wahl des kritischen Wertes
festgelegt werden. Der kritische Wert
ist dabei die Grenze zwischen Werten der Testgröße, die die
Nullhypothese bestätigen bzw. widerlegen. Eine zu starke
Verkleinerung des ![]() -Fehlers führt im Allgemeinen zu einer
unerwünschten Erhöhung des
-Fehlers führt im Allgemeinen zu einer
unerwünschten Erhöhung des ![]() -Fehlers.
-Fehlers.
Bei diesem Test
soll untersucht
werden, ob eine empirische Verteilungsfunktion
![]() (siehe Abschnitt
2.3.1) durch eine Verteilungsfunktion
(siehe Abschnitt
2.3.1) durch eine Verteilungsfunktion ![]() dargestellt werden kann.
dargestellt werden kann.
Die Nullhypothese ![]() lautet
lautet ![]() , die
Alternativhypothese
, die
Alternativhypothese ![]() lautet damit
lautet damit
![]() . Die
Testgröße
. Die
Testgröße ![]() lautet
lautet
| (17) |
wobei ![]() die Anzahl der Werte der empirischen
Verteilungsfunktion
die Anzahl der Werte der empirischen
Verteilungsfunktion ![]() ist.
ist.
Die Nullhypothese ![]() wird mit dem
wird mit dem ![]() -Fehler abgelehnt,
wenn
-Fehler abgelehnt,
wenn
![]() gilt. Die kritischen Werte
gilt. Die kritischen Werte
![]() können aus Tabellen entnommen werden (z.B.
[4] Seite 184).
können aus Tabellen entnommen werden (z.B.
[4] Seite 184).
Anschaulich bedeutet dies, dass die empirische
Verteilungsfunktion ![]() dann durch eine andere
Verteilungsfunktion
dann durch eine andere
Verteilungsfunktion ![]() angenähert werden kann, wenn
angenähert werden kann, wenn ![]() sich
innerhalb eines Gebietes der Breite
sich
innerhalb eines Gebietes der Breite
![]() um
um
![]() befindet. In den Abbildungen 4.13 und
4.32 ist dieses Gebiet zur Beurteilung der
Regression eingezeichnet.
befindet. In den Abbildungen 4.13 und
4.32 ist dieses Gebiet zur Beurteilung der
Regression eingezeichnet.
Mehrfeldtafeln sind matrizenförmig angeordnete Häufigkeiten.
Solche Tabellen werden auch als Kreuz- oder Kontingenztabellen
bezeichnet. Die einzelnen Werte der
![]() -Matrix werden
mit
-Matrix werden
mit ![]() bezeichnet.
bezeichnet.
Dieser Test untersucht, ob die ![]() gleich verteilt, d.h. die
gleich verteilt, d.h. die ![]() weder von
weder von ![]() noch von
noch von ![]() abhängen. Dazu wird folgende Testgröße berechnet:
abhängen. Dazu wird folgende Testgröße berechnet:
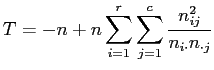 |
(18) |
Dabei ist
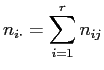 , , 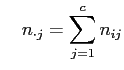 sowie sowie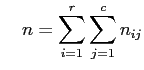 |
(19) |
Die Nullhypothese ![]() besagt, dass die
besagt, dass die ![]() stochastisch
unabhängig sind. Die Nullhypothese wird mit dem
stochastisch
unabhängig sind. Die Nullhypothese wird mit dem ![]() -Fehler
abgelehnt, wenn
-Fehler
abgelehnt, wenn
![]() .
.
![]() ist dabei
der kritische Wert, der von
ist dabei
der kritische Wert, der von ![]() -Fehler und Anzahl der
Freiheitsgrade der Matrix abhängt. Die
Anzahl der Freiheitsgrade lautet
-Fehler und Anzahl der
Freiheitsgrade der Matrix abhängt. Die
Anzahl der Freiheitsgrade lautet
![]() , wenn die
Randsummen
, wenn die
Randsummen
![]() und
und
![]() vorgegeben sind.
vorgegeben sind.
Die kritischen Werte
![]() sind hier genau die
sind hier genau die
![]() -Quantile der
-Quantile der ![]() -Verteilung für
-Verteilung für ![]() Freiheitsgrade.
Diese Werte sind leicht verfügbar (z.B. tabelliert in
[3] oder Berechnung mit Mathematica).
Freiheitsgrade.
Diese Werte sind leicht verfügbar (z.B. tabelliert in
[3] oder Berechnung mit Mathematica).
Mit Hilfe des Kontingenzkoeffizienten von Pawlik soll die Stärke
einer Korrelation innerhalb einer Kreuztabelle untersucht werden.
Zum Vergleich verschiedener Kreuztabellen ist die im vorherigen
Abschnitt vorgestellte Testgröße ![]() nicht geeignet, da sie
proportional zu
nicht geeignet, da sie
proportional zu ![]() ist. Diese Abhängigkeit weist der folgende
Kontingenzkoeffizient
ist. Diese Abhängigkeit weist der folgende
Kontingenzkoeffizient ![]() von Pawlik nicht auf (siehe
[3] Seite 601ff):
von Pawlik nicht auf (siehe
[3] Seite 601ff):
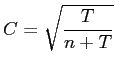 |
(20) |
Bei völliger Unabhängigkeit ist ![]() . Für den maximalen
Kontingenzkoeffizienten gilt
. Für den maximalen
Kontingenzkoeffizienten gilt
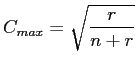 wobei bitte wobei bitte |
(21) |
Um die Kontingenzkoeffizienten von den Kreuztabellen unabhängig
und damit vergleichbar zu machen, wird der korrigierte
Kontingenzkoeffizient
![]() eingeführt. Es gilt
eingeführt. Es gilt
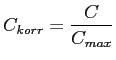 |
(22) |
Soll eine Stichprobe gepaarter Werte ![]() zweier
Zufallsvariablen
zweier
Zufallsvariablen ![]() und
und ![]() auf einen Zusammenhang von
auf einen Zusammenhang von ![]() und
und
![]() hin untersucht werden, so kann man auf Korrelationsmaße
zurückgreifen. Der normale Korrelationskoeffizient kann jedoch
nur lineare Zusammenhänge nachweisen und ist auf normalverteilte
Zufallsvariablen
hin untersucht werden, so kann man auf Korrelationsmaße
zurückgreifen. Der normale Korrelationskoeffizient kann jedoch
nur lineare Zusammenhänge nachweisen und ist auf normalverteilte
Zufallsvariablen ![]() und
und ![]() angewiesen (siehe [3] Seite
495).
angewiesen (siehe [3] Seite
495).
Der Spearmansche Rang-Korrelationskoeffizient kann dagegen bei Zufallsvariablen mit unbekannter Verteilung auch nichtlineare Zusammenhänge nachweisen. Er ist damit wesentlich vielseitiger einsetzbar (siehe [3] Seite 511f).
Bei Rang-Korrelationskoeffizienten werden nicht die ![]() und
und
![]() direkt untersucht sondern nur ihre Ränge. Der Rang
direkt untersucht sondern nur ihre Ränge. Der Rang
![]() eines Wertes
eines Wertes ![]() ist einfach die Position des Wertes
in der sortierten Liste aller
ist einfach die Position des Wertes
in der sortierten Liste aller
![]() .
Kommen einige
.
Kommen einige ![]() mehrfach vor, so spricht man von Bindungen.
Der Rang von gebundenen
mehrfach vor, so spricht man von Bindungen.
Der Rang von gebundenen ![]() ist der Mittelwert ihrer Positionen.
ist der Mittelwert ihrer Positionen.
Die Bestimmung der Rangzahlen für eine metrische Zufallsvariable kommt einer Skalentransformation einer metrischen Zufallsvariablen in eine ordinal skalierte Zufallsvariable gleich (siehe Abschnitt 2.3.1). Damit ist auch klar, warum mit diesem Korrelationskoeffizienten auch nichtlineare Zusammenhänge nachgewiesen werden können.
Der Spearmansche Rang-Korrelationskoeffizient berechnet sich für
![]() als
als
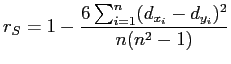
Für Zufallsvariablen mit vielen Bindungen (mehr als 20 % der Beobachtungen) steht noch ein korrigierter Koeffizient zur Verfügung (siehe [3] Seite 513), der hier aber nicht benötigt wird.
Um nun zwischen der Nullhypothese ![]() - zwischen
- zwischen ![]() und
und ![]() besteht kein Zusammenhang - oder der Alternativhypothese
besteht kein Zusammenhang - oder der Alternativhypothese ![]() - es besteht ein Zusammenhang - zu entscheiden, wird die
Testgröße
- es besteht ein Zusammenhang - zu entscheiden, wird die
Testgröße ![]() herangezogen. Die Nullhypothese wird auf dem
Signifikanzniveau
herangezogen. Die Nullhypothese wird auf dem
Signifikanzniveau ![]() abgelehnt, wenn
abgelehnt, wenn
![]() gilt.
Dabei können die kritischen Werte
gilt.
Dabei können die kritischen Werte
![]() aus [3]
(Seite 511) entnommen werden.
aus [3]
(Seite 511) entnommen werden.
Ein Ereignis ![]() und ein Ereignis
und ein Ereignis ![]() können gemeinsam auftreten.
Tun sie dies, so spricht man von einer Koinzidenz. Ist diese
Koinzidenz nicht zufällig, so spricht man von einer Korrelation.
Eine Korrelation kann aus verschiedenen Gründen vorliegen: zum
einen kann das Ereignis
können gemeinsam auftreten.
Tun sie dies, so spricht man von einer Koinzidenz. Ist diese
Koinzidenz nicht zufällig, so spricht man von einer Korrelation.
Eine Korrelation kann aus verschiedenen Gründen vorliegen: zum
einen kann das Ereignis ![]() das Ereignis
das Ereignis ![]() hervorrufen oder
umgekehrt. Es besteht auch die Möglichkeit, dass
hervorrufen oder
umgekehrt. Es besteht auch die Möglichkeit, dass ![]() und
und ![]() eine
gemeinsame Ursache haben.
eine
gemeinsame Ursache haben.
Die Assoziationsanalyse versucht nun die Korrelation von
Koinzidenzen zu bestimmen, d.h. sie versucht zu bestimmen, ob zwei
Ereignisse zufällig gemeinsam aufgetreten sind oder ob das eine
Ereignis das andere hervorgerufen oder beide Ereignisse eine
gemeinsame Ursache haben. Beispielsweise könnten Ereignis ![]() ,,das Gerät gehört zur Gerätegruppe der Infusionspumpen`` und
Ereignis
,,das Gerät gehört zur Gerätegruppe der Infusionspumpen`` und
Ereignis ![]() ,,das Gerät ist günstiger als 5000 `` lauten.
Dann könnte man jeweils die Anzahl der Geräte, für die Ereignisse
,,das Gerät ist günstiger als 5000 `` lauten.
Dann könnte man jeweils die Anzahl der Geräte, für die Ereignisse
![]() ,
, ![]() und beide Ereignisse
und beide Ereignisse ![]() und
und ![]() eintreten sowie die Anzahl aller Geräte bestimmen. Aus diesen
Anzahlen lassen sich zur Beurteilung der Korrelation der
Ereignisse
eintreten sowie die Anzahl aller Geräte bestimmen. Aus diesen
Anzahlen lassen sich zur Beurteilung der Korrelation der
Ereignisse ![]() und
und ![]() verschiedene Assoziationsmaße
berechnen, die die
Assoziationsanalyse bereit stellt. Im Folgenden sind einige
Assoziationsmaße aufgeführt, die in dieser Arbeit verwendet
wurden. Eine ausführliche Darstellung findet sich in [2] ab
Seite 427.
verschiedene Assoziationsmaße
berechnen, die die
Assoziationsanalyse bereit stellt. Im Folgenden sind einige
Assoziationsmaße aufgeführt, die in dieser Arbeit verwendet
wurden. Eine ausführliche Darstellung findet sich in [2] ab
Seite 427.
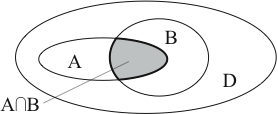
Er gibt an, wie häufig ein Ereignis im Verhältnis zu allen Ereignissen auftritt. Insbesondere ist der support des Ereignissen A und B treten gemeinsam auf für die Analysen wichtig. Wir schreiben
support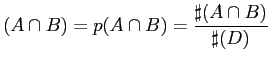 |
(23) |
Dabei sind mit
![]() die Wahrscheinlichkeit des
gleichzeitigen Eintretens von
die Wahrscheinlichkeit des
gleichzeitigen Eintretens von ![]() und
und ![]() bzw. die Anzahl der
Koinzidenzen von
bzw. die Anzahl der
Koinzidenzen von ![]() und
und ![]() gemeint und mit
gemeint und mit ![]() die
Anzahl aller Ereignisse.
die
Anzahl aller Ereignisse.
Dieses Maß ist zwar noch kein Assoziationsmaß, aber es gibt an, wie viele Ereignisse von einer noch eventuell zu entdeckenden Assoziation überhaupt betroffen sind, und ist damit für die Analysen nicht uninteressant. Außerdem wird dieses Maß als Baustein für die folgenden Maße wieder verwendet. Die Ereignismengen sind zur Veranschaulichung in Abbildung 2.3 dargestellt.
Sie ist nichts anderes als die bedingte Wahrscheinlichkeit des
Auftretens des Ereignisses ![]() unter der Voraussetzung des
Eintretens des Ereignisses
unter der Voraussetzung des
Eintretens des Ereignisses ![]() . Wir schreiben
. Wir schreiben
confidence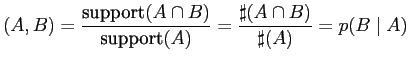 |
(24) |
In ungünstigen Fällen, kann die
confidence![]() hohe Werte annehmen, obwohl in der Ereignismenge kein
Zusammenhang zwischen den Ereignissen
hohe Werte annehmen, obwohl in der Ereignismenge kein
Zusammenhang zwischen den Ereignissen ![]() und
und ![]() besteht. Dies
ist dann der Fall, wenn
support
besteht. Dies
ist dann der Fall, wenn
support![]() groß ist - dann ist
auch
confidence
groß ist - dann ist
auch
confidence![]() bei nicht vorhandener Korrelation
der Ereignisse
bei nicht vorhandener Korrelation
der Ereignisse ![]() und
und ![]() groß. Diesen Nachteil versucht der
lift zu umgehen.
groß. Diesen Nachteil versucht der
lift zu umgehen.
Dieser ergibt sich als Quotient von
confidence![]() und
support
und
support![]() . Wir schreiben
. Wir schreiben
lift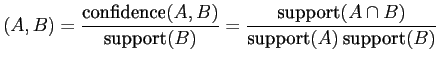 |
(25) |
Der lift gibt damit das Verhältnis von beobachteten
Koinzidenzen
support![]() und von den bei
Gleichverteilung zu erwartenden Koinzidenzen als Produkt von
support
und von den bei
Gleichverteilung zu erwartenden Koinzidenzen als Produkt von
support![]() und
support
und
support![]() . Also ist der lift ein
Maß dafür wie viel eine beobachtete Koinzidenz häufiger bzw.
seltener ist, als sie bei Gleichverteilung zu erwarten wäre. Er
ist damit weniger ein direktes Maß für die Abhängigkeit zwischen
. Also ist der lift ein
Maß dafür wie viel eine beobachtete Koinzidenz häufiger bzw.
seltener ist, als sie bei Gleichverteilung zu erwarten wäre. Er
ist damit weniger ein direktes Maß für die Abhängigkeit zwischen
![]() und
und ![]() , als vielmehr ein Maß für die Abweichung der
Unabhängigkeit.
, als vielmehr ein Maß für die Abweichung der
Unabhängigkeit.
Leider lassen sich für den lift auch Fälle konstruieren, an denen
er als Assoziationsmaß versagt: wenn
confidence![]() und
support
und
support![]() etwa gleich groß sind, dann ergibt sich auch
bei hoher confidence ein lift von etwa eins - was trotz der
hohen confidence hier auf einen geringen Zusammenhang hindeutet.
etwa gleich groß sind, dann ergibt sich auch
bei hoher confidence ein lift von etwa eins - was trotz der
hohen confidence hier auf einen geringen Zusammenhang hindeutet.
Man könnte noch ein weiteres Assoziationsmaß einführen - die conviction -, das diesen Nachteil nicht besitzt. Jedoch besitzt diese Maß eine nicht mehr so anschauliche Interpretation wie die des liftes und wird deshalb in dieser Arbeit nicht verwendet.
Betrachten wir ein System, dass sich zu diskreten Zeitpunkten
![]() beliebig in einem der Zustände
beliebig in einem der Zustände ![]() befinden kann. Die
Zustände, in denen sich das System zum Zeitpunkt
befinden kann. Die
Zustände, in denen sich das System zum Zeitpunkt ![]() befindet,
werden mit
befindet,
werden mit ![]() bezeichnet.
bezeichnet.
Nun kann man eine Übergangswahrscheinlichkeit
![]() als bedingte
Wahrscheinlichkeit einführen, dass auf dem Zustand
als bedingte
Wahrscheinlichkeit einführen, dass auf dem Zustand ![]() der
Zustand
der
Zustand ![]() folgt. Diese Wahrscheinlichkeiten lassen sich
übersichtlich in einer Übergangsmatrix
folgt. Diese Wahrscheinlichkeiten lassen sich
übersichtlich in einer Übergangsmatrix
![]() darstellen.
darstellen.
Hängen die ![]() nicht von der Zeit ab (Homogenität der Zeit),
so kann man die
nicht von der Zeit ab (Homogenität der Zeit),
so kann man die ![]() als markowsche Kette auffassen (siehe
[5] Seite 1084).
als markowsche Kette auffassen (siehe
[5] Seite 1084).
Erst seit gut 50 Jahren wird Sprache nicht nur qualitativ sondern auch mit quantitativen Methoden untersucht - in der Linguistik kann nun also wie bei anderen Wissenschaften auch ,,gemessen`` werden. Gemessen werden dabei hauptsächlich Häufigkeiten von sprachlichen Objekten wie Wörtern und Buchstaben. Aus diesen Daten wird dann mit Hilfe statistischer Methoden versucht, neue Erkenntnisse zu gewinnen oder bekannte Vermutungen zu begründen. Als Geburtsstunde dieser Entwicklung wird das Zipf'sche Gesetz angesehen.
Das Zipf'sche Gesetz beschreibt in sehr einfacher Weise die
Häufigkeitsverteilung von Worten in Texten. Dazu formuliert das
Gesetz einen Zusammenhang zwischen der Häufigkeit ![]() eines
Wortes in einem (ausreichend langen) Text und seines nach
Häufigkeit sortierten Ranges
eines
Wortes in einem (ausreichend langen) Text und seines nach
Häufigkeit sortierten Ranges ![]() als (siehe [6])
als (siehe [6])
Dabei passt der Parameter ![]() die Verteilung an
verschiedene Textumfänge an und der Formparameter
die Verteilung an
verschiedene Textumfänge an und der Formparameter ![]() bestimmt
die Form der Verteilung. Für gewöhnliche Texte liegt
bestimmt
die Form der Verteilung. Für gewöhnliche Texte liegt ![]() meist
etwas über 1 und kann näherungsweise ganz entfallen.
meist
etwas über 1 und kann näherungsweise ganz entfallen.
Durch Logarithmieren erhält man mit
![]() eine einfach zu untersuchende Geradengleichung.
eine einfach zu untersuchende Geradengleichung.
Trotz seiner einfachen Form ist das Gesetz erstaunlich gut in der Lage, Häufigkeitsverteilungen verschiedenster Objekte zu beschreiben. Der Grund dafür ist bis heute nicht verstanden. Da es sich beim Zipf'schen Gesetz um ein empirisches Gesetz handelt, gilt es nicht exakt. Oft liefert aber auch die Abweichung einer Verteilung vom Zipf'schen Gesetz wertvolle Informationen.
Die dem Zipf'schen Gesetz zugrunde liegende Verteilungsfunktion wird als Zeta-Verteilung bezeichnet.
Als mächtiges Werkzeug bei der quantitativen Analyse von Texten
erweist sich die Entropie. Die Entropie kann als Maß der
Unordnung einer Verteilung angesehen werden. Für die oben
genannten Worthäufigkeiten ![]() ergibt sich die Entropie h mit
ergibt sich die Entropie h mit
![]() zu
zu
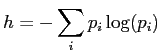 |
(27) |
Bemerkenswert ist, das die Entropie die Unordnung als Informationsgehalt pro betrachtetem Element angibt - also hier pro Wort. Benutzt man zur Berechnung der Entropie den Logarithmus zur Basis 2, so gibt die Entropie den Informationsgehalt pro Wort in Bit an. Je größer also die Unordnung in einem Text ist, desto mehr Information wird pro Wort übertragen.
Ist der absolute Wert der Entropie nicht von Interesse, so kann
man eine relative Entropie ![]() einführen. Es gilt
einführen. Es gilt
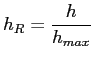 |
(28) |
Dabei ist ![]() die maximale Entropie, die die
betrachtete Wortgruppe annehmen kann. Man kann sich leicht
überlegen, dass die Entropie bei Gleichverteilung
maximal wird, d.h. alle
die maximale Entropie, die die
betrachtete Wortgruppe annehmen kann. Man kann sich leicht
überlegen, dass die Entropie bei Gleichverteilung
maximal wird, d.h. alle ![]() sind gleich
groß, und es gilt
sind gleich
groß, und es gilt ![]() , wenn
, wenn ![]() die Anzahl der
verschiedenen Wörter ist. Damit wird
die Anzahl der
verschiedenen Wörter ist. Damit wird
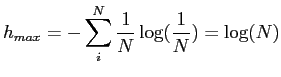 |
(29) |