Bei normierten Daten werden gleiche oder genauer als gleich angesehene Dinge auch gleich bezeichnet. Zum Beispiel schreibt der eine bei nicht normierten Daten ,,Mausefalle`` und der andere ,,Falle, Klapp- für Nagetier, grau``.
Hierbei sind zwei Entscheidungen zu Treffen: 1. welche Begriffe sollen zusammengefasst werden und 2. mit welchem Begriff soll diese Zusammenfassung benannt werden. Man kann die eine Frage nicht beantworten, ohne über die Antwort der anderen Frage zu verfügen. Die Fragen lassen sich also nicht nach einander beantworten - vielmehr müssen die Antworten in einem iterativen Prozess gefunden werden. Mehr jedoch dazu später.
Wünschenswert ist natürlich auch, dass nicht nur gleiche Dinge ,,gleich`` bezeichnet werden, sondern auch Unterschiedliche ,,unterschiedlich``. Handelt es sich zum Beispiel bei einem Monitor um einen Patienten- oder um einen Computer-Monitor? Obwohl grundsätzlich gilt, dass dieses Fehlen an Detailinformation in den Daten nicht im Rahmen dieser Untersuchung behoben werden kann, so kann man es jedoch manchmal dadurch etwas abfangen, dass man Begriffe verwendet, die über eine hierarchische Struktur verfügen - für die es also Ober- und Unterbegriffe gibt. Dann kann bei ungenauer Beschreibung einfach ein ungenauerer Oberbegriff verwendet werden, und diese vorhandene Teilinformation kann dann genutzt und muss nicht verworfen werden.
Da es durchaus vorkommen kann, dass zu einem Zellinhalt der Originaldaten mehrere verschiedene normierte Begriffe zugeordnet werden, werden sämtliche Zuordnungen im folgenden Format gespeichert: Zu jedem gefundenen normierten Begriff werden in einer neuen Tabelle das zugehörige Merkmal (bzw. die zugehörige Spalte), die zugehörige Zeile und die zugehörige Tabelle gespeichert. Dies hat auch den Vorteil, das nicht zu jeder Zelle der Originaldaten ein Datensatz angelegt werden muss, wenn kein normierter Begriff zugeordnet werden kann - dies spart Speicherplatz. Der Nachteil, dass Datenbankabfragen der neuen Tabellen länger brauchen, fällt bei der Erstellung der Tabellen noch nicht ins Gewicht.
Das eben Gesagte gilt nur für kategoriale bzw. nominal skalierte Merkmale. Wenn im folgenden von der Normierung metrischer Größen gesprochen wird, so sind eher ein Import in ein einheitliches Datenformat und eine gleichzeitige Validitätsprüfung der Daten gemeint.
Metrische Merkmale lassen sich leichter analysieren als nominal skalierte Merkmale, da für diese arithmetische Operationen zur Verfügung stehen. Diesen Vorteil kann man aber nur dann nutzen, wenn die Daten in einem Variablenformat gespeichert sind, das Rechenoperationen zulässt. Deshalb ist es nötig, die im Textformat vorliegenden metrischen Größen in ein neues Variablenformat zu transformieren.
Kaufpreise oder Durchführungskosten von Maßnahmen, die in den Originaldaten noch in Deutsche Mark angegeben sind, werden ins Integerformat oder Ganzzahlformat gewandelt und in Euro umgerechnet. Die Ungenauigkeit durch das nötige Runden sind vertretbar. Beim Umwandeln ist auf wechselnde Dezimaltrennungszeichen (Punkt oder Komma) zu achten. Kaufpreise unter 100 oder über 10 Mio. werden ignoriert. Bei Kosten von Maßnahmen werden Beträge von 10 bis 1 Mio. akzeptiert.
Datumsangaben wie das Kaufdatum oder der Durchführungszeitpunkt können durch einen Trick verlustfrei in das Integerformat gewandelt werden: statt der unterschiedlichen Schreibweisen ,,28-06-1993`` oder ,,19. Juni. 98`` etc werden einfach die vergangenen Tage nach dem 01.01.1900 ganzzahlig abgespeichert. Dies ist für die direkte Lesbarkeit der Daten zwar nicht förderlich, vereinfacht die Analyse jedoch erheblich. Es werden nur Datumsangaben zwischen dem 01.01.1900 und dem 01.01.2002 akzeptiert. Bei dieser Umwandlung ist viel Handarbeit nötig.
Die hier zu normierenden kategorialen Merkmale liegen in Freitext-Form vor, d.h. oft sind es Teilzeichenketten oder Stichwörter, die über die Einordnung entscheiden. Zunächst geht es darum, diese Stichwörter zu finden, um sie dann in Gruppen einzuteilen. Auf diese Weise löst sich auch das Problem der unterschiedlichen Bezeichnung bei Verwendung von Synonymen.
Zunächst werden die Spalten ,,Abteilung``, ,,Hersteller`` und ,,Arbeitsbeschreibung`` in getrennte Textdateien exportiert. Die Spalte ,,Gerätebezeichnung`` wird später gesondert behandelt. Dies verkleinert die Größe der zu verarbeitenden Dateien. Die Zellinhalte werden jeweils als einzelne Zeile gespeichert.
In diesen Dateien werden nun alle Leerzeichen durch Tiefstriche (,,_``) ersetzt und zusätzlich am Ende und am Anfang jeder Zeile ein Tiefstrich eingefügt. Das Einfügen am Ende und am Anfang einer Zeile führt dazu, dass ein Wortende oder -anfang am Anfang bzw. am Ende einer Zeile im folgenden nicht anders behandelt wird als ein Wortanfang oder -ende mitten in einer Zeile.
Im nächsten Schritt wird nun jede Zeile in überlappende Teilzeichenketten der Längen 4 bis 25 Zeichen zerlegt, die zeilenweise in eine neue Datei geschrieben werden. Aus der Zeile _pumpe_ z.B. werden so die folgende Zeilen (hier durch Komma getrennt) generiert:
_pumpe_, _pumpe, pumpe_, _pump, pumpe, umpe_, _pum, pump, umpe, mpe_
Teilzeichenketten, die länger als 25 oder kürzer als 4 Zeichen sind, werden nicht generiert, weil die langen Zeichenketten zu selten auftreten und die kurzen kaum Information transportieren. Außerdem würden die kurzen Teilzeichenketten wegen ihrer großen Anzahl die Verarbeitung erheblich verlangsamen.
Nun wird zu jeder eben erstellten Teilzeichenkettenliste eine Liste aller vorkommenden Teilzeichenketten jeweils mit Häufigkeit erstellt. Aus technischen Gründen (Access kann keine Datenbanken größer als 2 GB verarbeiten) werden Teilzeichenketten, die seltener als 10 mal auftauchen, nicht weiter berücksichtigt. Die weiteren Analysen werden dadurch kaum beeinflusst.
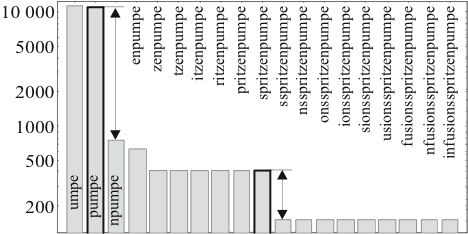
Mit Hilfe dieser Häufigkeitstabellen kann nun die Häufigkeit der häufigsten Zeichenkette ermittelt werden, die eine bestimmte Zeichenkette enthält. Hierzu ein Beispiel: die Zeichenkette ,,umpe_`` tritt 11 284 mal auf. Die häufigste Zeichenkette, die die Zeichenkette ,,umpe_`` enthält ist ,,pumpe`` mit Häufigkeit 11 230. Diese häufigste Zeichenkette ist immer um ein Zeichen länger als die ursprüngliche Zeichenkette. Diese Zahlen werden nun für jede Teilzeichenkette bestimmt.
Bildet man nun die Differenz zwischen der ermittelten Häufigkeit einer Teilzeichenkette und der Häufigkeit der häufigsten umfassenden Teilzeichenkette, so zeigt sich, dass Teilzeichenketten, die eine große Differenz aufweisen, für die weiteren Analysen von Interesse sind. Woran liegt das?
In der Abbildung 3.2 sind ausgehend von der Teilzeichenkette ,,umpe`` jeweils die häufigsten umfassenden Teilzeichenketten mit Häufigkeit angegeben. Man sieht, dass die Häufigkeiten von Teilzeichenketten, die interessante Teilzeichenketten (,,pumpe``, ,,spritzenpume``) umfassen, stärker abfallen als andere.
Im Deutschen werden Begriffe aus verschiedenen Worten, Präpositionen oder Wortteilen zusammengesetzt. Wird ein zusammengesetzter Begriff nun Buchstabe für Buchstabe aufgebaut, so gibt es beim Anfügen von Buchstaben innerhalb der Wortteile kaum Variationsmöglichkeiten. Wenn jedoch ein Wortteil fertig aufgebaut ist, dann stehen beim nächsten Buchstaben viele Möglichkeiten zur Verfügung, weil der Wortteil mit vielen anderen Wortteilen kombiniert werden kann. Dadurch, dass viele Möglichkeiten bestehen, ist die Anzahl, mit der die einzelnen Möglichkeiten eintreten, kleiner und damit die Differenz zwischen den Anzahlen höher.
|
Für das Merkmal ,,Arbeitsbeschreibung`` ergibt sich damit Tabelle 3.8. Es sind die Teilzeichenketten nach Häufigkeit sortiert. Wie man sieht, ist die Häufigkeit kein gutes Kriterium für interessante Teilzeichenketten. In der nächsten Tabelle 3.9 sind die Teilzeichenketten nach Differenz sortiert. Schon an dieser kleinen Auswahl ist deutlich zu sehen, dass der Anteil interessanter Teilzeichenketten größer ist.
Die Einteilung der gefundenen Begriffe in die Gruppen Objekt, Verb und Attribut erleichtert die Gruppierung von Synonymen und die anschließende Vergabe eines gemeinsamen, normierten Begriffes. Insgesamt wurde ein Zeitaufwand von ca. 100 Tagen in diese Arbeiten investiert. 60% der Zeit flossen in das Finden eines oben beschriebenen Algorithmus, der die Datenmengen überhaupt verarbeitbar macht; 30% der Zeit wurde für das Finden von Oberbegriffen benötigt, die die vorhanden Informationen knapp aber ausreichend detailliert zusammenfassen; die restlichen 10% der Zeit wurden für das Zuordnen der normierten Begriffe zu den vorhandenen Teilzeichenketten benötigt.
Die Trennung zwischen dem Finden normierter Begriffe und dem Zuordnen dieser ist nicht so scharf möglich, wie die obigen Zeitangaben vielleicht vermuten lassen. Wie schon im vorherigen Abschnitt angedeutet wurde, ist das Finden und Zuordnen von Begriffen ein iterativer Prozess. Ohne Begriffe kann man nichts zuordnen - jedoch kann man ohne Zuordnungen auch nicht entscheiden, welche Begriffe die vorliegenden Daten gut zusammenfassen.
Versucht man, die normierten Begriffe zu systematisieren, so stellt man bei der Zuordnung fest, dass man sehr unterschiedlich und schwach besetzte Gruppen erhält. Orientiert man sich an den Häufigkeiten der Nennungen in den Originaldaten, so erhält man sehr unsystematische normierte Begriffe. Eine Normierung kann immer nur ein Kompromiss zwischen diesen Extremen sein.
Die in dieser Arbeit verwendeten normierten Arbeitsbeschreibungen sind im Anhang B.1 mit den ihnen zugeordneten Teilzeichenketten angegeben. Eine Maßnahme kann selbstverständlich mehreren normierten Arbeitsbeschreibungen zugeordnet werden.
![\begin{table}\centering
\includegraphics[width=11cm]{eps/norm_2}
\end{table}](img231.png) |
![\begin{table}\centering\includegraphics[width=11cm]{eps/norm_3}
\end{table}](img232.png) |
Beim Merkmal ,,Hersteller`` kann genau wie beim Merkmal ,,Arbeitsbeschreibung`` vorgegangen werden. Der einzige vereinfachende Unterschied ist, das interessante Teilzeichenketten praktisch immer begrenzt durch ,,_`` vorliegen, was die Anzahl der durchzusehenden Teilzeichenketten erheblich verringert. Insgesamt wurden etwa 800 unterschiedliche Firmen zugeordnet.
Auch beim Merkmal ,,Abteilung`` kann genau wie beim Merkmal ,,Arbeitsbeschreibung`` vorgegangen werden. Auch hier sind viele wichtige Stichworte abgekürzt oder liegen in zusammengesetzter Form (,,kinderchirurgie`` statt ,,paediatrie`` und ,,chirurgie``) vor. Damit ist klar, dass eine originale Abteilungsbezeichnung mehreren normierten Abteilungen zugeordnet werden kann. Insgesamt wurden 76 unterschiedliche Abteilungen zugeordnet.
Die bis jetzt erstellten Zuordnungen von Teilzeichenketten zu den einheitlichen Begriffen müssen nun noch auf die Daten angewendet werden. Dazu werden die Zuordnungen in Textdateien exportiert, die die Teilzeichenkette und die Zuordnung als Spalte enthalten.
Diese Dateien werden auf überflüssige oder widersprüchliche
Zuordnungen durchsucht. Eine überflüssige Zuordnung liegt vor,
wenn es eine identische Zuordnung mit kürzerer Teilzeichenkette
gibt (z.B. ist die Zuordnung ,,_repera``
![]() ,,Reparatur`` überflüssig, wenn es eine Zuordnung ,,_rep``
,,Reparatur`` überflüssig, wenn es eine Zuordnung ,,_rep``
![]() ,,Reparatur`` gibt).
,,Reparatur`` gibt).
Eine widersprüchliche Zuordnung liegt vor, wenn es zwei unterschiedliche Zuordnungen mit gleicher Teilzeichenkette gibt.
Im Rahmen dieser Arbeit wurde erst versucht, mit dem eben geschilderten Vorgehen, einen normierten Gerätekatalog aufzustellen. Diese Versuche mussten jedoch aufgegeben werden, da ein solcher Katalog zu viele Begriffe enthält und darüber hinaus auch noch eine Gruppierung in Gerätearten zulassen sollte - dies war vom Arbeitsaufwand her nicht im Rahmen dieser Arbeit zu bewältigen.
Aus diesem Grunde wurde versucht, mit bereits fertigen Gerätekatalogen zu arbeiten. Aus den getesteten Katalogen konnte besonders der EMTEC-Katalog überzeugen, da er schon von Haus aus Synonyme mitbringt und eine sehr übersichtliche Struktur in vier Hierarchieebenen besitzt.
Zwar macht das Vorhandensein eines Kataloges die mühselige, kaum zu systematisierende Tätigkeit beim Erstellen eines neuen Kataloges überflüssig, aber dafür wird das Assoziieren der Gerätebezeichnungen mit den vorhandenen Daten schwieriger, weil der normierte Begriffskatalog nicht mehr aus dem Datenbestand gewachsen ist, auf den er angewendet werden soll. Aus diesem Grunde unterscheidet sich das Vorgehen beim Normieren des Merkmales ,,Gerätebezeichnung`` von den anderen kategorialen Merkmalen.
Zunächst muss der EMTEC-Katalog für die weitere Verarbeitung importiert werden. Da er auch als Textdatei vorliegt, ist der Import problemlos möglich. Als zweckmäßiges Format, das alle für die folgenden Analysen notwendigen Informationen enthält, hat sich eine Textdatei herausgestellt, die die Spalten
enthält. Alle weiteren Informationen des Kataloges werden im folgenden nicht benötigt.
Eine erste Analyse dieser Textdatei zeigt, dass die vier Hierarchieebenen des EMTEC-Katalogs folgende Anzahlen an Gerätearten besitzt (die Anzahl der Gerätearten aus der Medizintechnik (MT) sind in Klammern angegeben):
Diese Anzahl an Gerätearten steht einer Anzahl von über 150 000 Geräte-Entitäten aus der Datenbank gegenüber. Manuell sind Zuordnungen dieser Größenordnung im Rahmen dieser Arbeit nicht mehr möglich. Aus diesem Grunde wird auch hier das Verfahren weitgehend automatisiert. Dies führt auch zu einer weniger subjektiven Zuordnung.
Zunächst werden gleiche Gerätebezeichnungen in den Originaldaten zusammengefasst und mit Häufigkeit versehen in einer neuen Textdatei gespeichert. Die Anzahl der verschiedenen Gerätebezeichnungen beträgt immerhin nur noch 11 105.
Wie beim Normieren der anderen kategorialen Merkmale werden die Gerätebezeichnungen des EMTEC-Kataloges und der Originaldaten nach Säubern und Begrenzen mit Tiefstrichen (,,_``, siehe Normierung der Gerätebezeichnung) jeweils in überlappende Dreier-Teilzeichenketten (Trigramme) zerlegt. Dann werden die übereinstimmenden Dreier-Teilzeichenketten für jede Kombination von Originalgerätebezeichnung und EMTEC-Gerätebezeichnung bestimmt ([14] Seite 386).
Mit Hilfe dieser Informationen sollen die besten Übereinstimmungen von EMTEC-Bezeichnungen und originalen Gerätebezeichnungen gefunden werden. Als Gütekriterium die Anzahl der übereinstimmenden Dreier-Teilzeichenketten zu verwenden, erweist sich als ungünstig, da längere Begriffe dabei bevorzugt werden - was nicht immer erwünscht ist. Auch das Heranziehen der Anzahl der untereinander unterschiedlichen, aber in beiden Begriffen übereinstimmenden Teilzeichenketten zeigt nicht so gute Ergebnisse wie folgendes Vorgehen: Es wird die Anzahl der Buchstaben der EMTEC-Bezeichnung ermittelt. Dann wird ermittelt, welche Buchstaben in identischen Dreier-Teilzeichenketten aus der Original-Bezeichnung enthalten sind. Ist ein Buchstabe in mehreren Teilzeichenketten enthalten, so wird er nur einmal gezählt. Das Verhältnis von betroffenen zu allen Buchstaben der EMTEC-Bezeichnung ist ein brauchbares Kriterium zur Beurteilung der Ähnlichkeit.
Es werden mit dieser Methode auch die EMTEC-Bezeichnungen durchsucht, die als Synonym gekennzeichnet sind. Die Synonyme werden jedoch nicht selber als normierte Begriffe verwendet, sondern nur den Synonymen zugeordnete EMTEC-Hauptbegriffe.
Die jeweils 20 besten Treffer aus dem EMTEC-Katalog werden je einer Gerätebezeichnung aus den Originaldaten zugeordnet und mit Quotient in einer Textdatei gespeichert. Diese Textdatei kann man in Access importieren und unter Verwendung von Unterdatenblättern übersichtlich darstellen (siehe Tabelle 3.10).
Durch die in der Access-Datenbank abgelegten Informationen lassen sich Gerätebezeichnungen effektiv normalisieren. Zuerst werden per Datenbank-Abfrage Gerätebezeichnungen mit einer bestimmten Zeichenfolgenkombination (wie z.B. ,,defi`` und ,,moni`` in Tabelle 3.10) per Auswahlabfrage aus allen Gerätebezeichnungen selektiert, um dann gemeinsam über eine der gefundenen EMTEC-Bezeichnungen zugeordnet zu werden - man muss also nicht für jede Gerätebezeichnung nach der besten Zuordnung einzeln suchen. Die Zuordnung zu den EMTEC-Bezeichnungen kann Dank der im Unterdatenblatt angegebenen 20 besten Treffer schnell und effizient erfolgen.
Insgesamt waren hierfür ca. 60 Tage Arbeit nötig. Etwa 70% der Zeit wurde für das Finden eines geeigneten Verfahrens benötigt, das diese Datenmengen verarbeitbar macht. In der restlichen Zeit wurde dann die eigentliche Normierung durchgeführt.
Wie bei den anderen kategorialen Merkmalen müssen die erstellten Zuordnungen von Originalbegriffen zu den EMTEC-Begriffen nun noch auf die Daten angewendet werden. Dazu werden auch hier die Zuordnungen in Textdateien exportiert, die die Originalbezeichnung und die Zuordnung als Spalte enthalten.
Eine Überprüfung dieser Dateien auf überflüssige oder widersprüchliche Zuordnungen ist hier nicht nötig. Jeder Zelle der Originaldaten wird nach passenden Zuordnungen durchsucht. Wird eine passende gefunden, so wird die Fundstelle wieder durch Angabe der eindeutigen Kennung (Zeile) und Merkmal (Spalte) gekennzeichnet und in einer neuen Textdatei abgelegt.
![\begin{table}\centering \centering\includegraphics[width=15cm]{eps/norm4}
\end{table}](img233.png) |
Alle Zuordnungen von Originaldaten und normierten Begriffen liegen nun in einem einheitlichen Format vor: immer, wenn ein Originalbegriff durch einen normierten Begriff ersetzt werden kann, so sind in einer Tabelle die Zeile, Spalte und der normierte Begriff angegeben. Aus diesen Informationen lassen sich Tabellen konstruieren, die genauso aufgebaut sind wie die Originaldaten, jedoch die normierten Begriffe enthalten.
Diese Tabellen werden als Grundlage für die weiteren Analysen in einer Access- Datenbank abgelegt.