Nachdem die Daten vorbereitet sind, können sie auf ihre Struktur untersucht werden. Dabei geht es jetzt noch nicht um Bedeutungen (Semantik), sondern nur um die Darstellung (Syntax). Das Ergebnis dieser Analysen würde sich nicht ändern, wenn man jeden Buchstaben (jedoch bitte eindeutig) durch einen anderen ersetzen würde: die semantischen Informationen würden dabei verloren gehen, der Syntax der Daten bleibt jedoch unberührt.
Der Hauptvorteil dieser Analysen ist gleichzeitig auch der Hauptnachteil: dadurch, dass man die Bedeutungen der Daten ausblendet, ignoriert man viele Informationen, begeht aber garantiert keinen Interpretationsfehler bei der Zuordnung von Bedeutungen zu den Daten. Die Analyse ist also ungenau, aber robust.
Zu jeder Datenbank, zu jeder Tabelle und zu jeder Spalte aus den Originaldaten werden Struktur-Informationen ermittelt und in einer Tabelle jeweils in einer Zeile abgelegt. Ein Ausschnitt dieser Daten ist in Tabelle 3.3 angegeben. Die Struktur-Informationen sind dabei im einzelnen:
Zusätzlich werden in einer weiteren Tabelle zu jeder internen Referenznummer aus der vorherigen Tabelle alle unterschiedlichen Zellen jeweils mit Häufigkeit abgelegt. Beispielhaft sind dazu die unterschiedlichen Zellinhalte der Spalte ,,art`` aus der Tabelle ,,DURCH120`` aus der Datenbank ,,22`` in der Untertabelle von Tabelle 3.3 absteigend nach Häufigkeit sortiert dargestellt. Diese beiden Tabellen werden als leicht zugängliches Zwischenergebnis in eine Access-Datenbank importiert und verknüpft und dienen damit als Arbeitsgrundlage für das weitere Vorgehen.
![\begin{table}\centering
\includegraphics[width=11cm]{eps/strukt_3}
\end{table}](img226.png) |
Aus den oben erstellten Tabellen lässt sich leicht ermitteln, dass 50 % der Zellen, 42 % aller Spalten und 43 % aller Tabellen leer sind. Die 22 Mio. nicht leeren Zellen enthalten 450 000 verschiedene Zellinhalte. Man sieht, in den Daten ist eine Menge ,,Luft``. Um Spalten zu finden, die interessante Informationen bieten, kann man zunächst Spalten auswählen, die mehr als 10 Zellen enthalten. Dies sind 5137 Spalten (ca. 51 % aller Spalten). Davon enthalten
Von diesen 2059 Spalten, die mehr als 10 Zellen enthalten und wiederum zu weniger als 10 % leer sind, enthalten
Also bleiben 2059 - 391 - 854 = 814 Spalten (ca. 18 % - 3.5 % - 7.5 % = 7 % aller Spalten, also ca. 35 Spalten pro Datenbank), die
Die Datenbanken enthalten also viele ungenutzte Spalten. Außerdem beträgt der Anteil der leeren Zellen bei obiger Auswahl ca. 23%. D.h. der Anteil leerer Zellen ist in dieser Auswahl halb so groß wie bei allen Zellen.
Durch diese Spalten-Anforderungen schrumpft die Anzahl der interessanten Spalten auf ein Maß zusammen, das mit vertretbarem Aufwand manuell weiter untersuchbar ist. So können - wie im Abschnitt 3.3.3 dargestellt - Spalten zu Gruppen zusammengefasst werden, wobei jede Gruppe nur aus Spalten besteht, die Informationen zu einem bestimmten Merkmal enthalten (wie z.B. Gerätebezeichnung).
Unterstellt sei, dass diese Informationen jetzt schon vorliegen: In der Tabelle 3.4 sind Informationen einiger ausgewählter kategorialer Merkmale von Geräten und Tätigkeiten aufgeführt. Jeweils angegeben sind die Mittelwerte mit Standardabweichungen aller Spalten, die Informationen zu einem Merkmal enthalten. Die Anzahl der ,,unterschiedlichen Zellen`` pro Spalte und ,,einmaligen Zellen`` sind als prozentuale Anteile aller Zellen einer Spalte dargestellt.
Aus dieser Tabelle ist ableitbar, dass jede 5. (20.53 %) Eintragung im Feld ,,Anlagenbezeichnung`` vorher noch nicht verwendet wurde. Jede 2. (10.77 % / 20.53 %) neu eingeführte Bezeichnung wird danach nicht mehr verwendet.
Für die anderen Merkmale gelten die selben Überlegungen. Daraus folgt: es werden bedenklich viele unterschiedliche Bezeichnungen verwendet, insbesondere bei den Merkmalen ,,Anlagenbezeichnung`` und ,,Tätigkeitsart``. Bei dieser großen Zahl von verschiedenen Bezeichnungen ist zu vermuten, dass auch als gleich anzusehende Dinge unterschiedlich bezeichnet werden. Dies erschwert eine Analsyse der Daten erheblich.
Die hohen Standardabweichungen des Mittelwertes bei den Merkmalen ,,Tätigkeitsart`` und ,,Arbeitsbeschreibung`` deuten auf eine Unabhängigkeit der Anzahl der unterschiedlichen und einmaligen Zellen aus der Anzahl aller Zellen hin. Bei der hohen Anzahl von Tätigkeiten werden bei Neueintragungen kaum noch neue Begriffe eingeführt (Sättigung).
Bei dem Merkmal ,,E/F-Leistung`` ist jeder 1000. Eintrag ein neuer Eintrag. In den Tabellen überwiegen 3 verschiedene Eintragungen: jeweils für ,,Eigenleistung``, ,,Fremdleistung`` und ,,leer``. Daraus folgt: Bei einfachen Eingabealternativen wird vermutlich durch Eingabemasken ein hohes ,,Begriffs-Recycling`` erreicht.
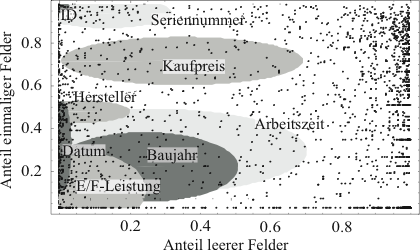
Trägt man für jede der über 10 000 Spalten jeweils den Anteil der leeren Felder und der einmaligen Felder an allen Feldern einer Spalte auf, so erhält man die Abbildung 3.1. Es ist zu erkennen, dass sich viele Spalten in den Randbereichen befinden. Durch Ellipsen sind die Bereiche angedeutet, in denen sich gehäuft Spalten bestimmter Merkmale befinden.
| unterschiedliche Zellen | einmalige Zellen | |||
| Mittelwert | StdAbw | Mittelwert | StdAbw | |
| Merkmal (Geräte) | ||||
| Gerätebezeichnung | 20,53% | 6,91% | 10,77% | 4,94% |
| Typ/Modell | 42,30% | 15,40% | 31,26% | 16,41% |
| Hersteller | 14,21% | 5,32% | 6,71% | 2,55v |
| Standort, Abteilung | 4,59% | 3,14% | 1,27% | 1,69% |
| Merkmal (Maßnahmen) | ||||
| Tätigkeitsart | 8,37% | 20,73% | 5,26% | 15,96% |
| Arbeitsbeschreibung | 25,68% | 21,04% | 23,38% | 19,96% |
| E/F-Leistung | 0,10% | 0,07% | 0,03% | 0,02% |
| Firma | 2,68% | 1,56% | 0,97% | 0,66% |
|
Mit Hilfe der im vorherigen Abschnitt gewonnen Informationen (welche Spalten sind interessant, was sind die häufigsten Zellinhalte) können nun die Spalten der einzelnen Tabellen zu Gruppen zusammengefasst werden. Eine Gruppe enthält dann alle Spalten eines Merkmales einer Entität. Der Auswahlprozess findet manuell statt und hat ca. 30 Stunden gedauert.
Ob zu einem Merkmal eine Gruppe gebildet wird, die alle Spalten mit dem Merkmal enthält, hängt davon ab, ob das betreffende Merkmal für die weiteren Analysen potentiell interessant ist und ob überhaupt ausreichend viele Spalten in den Daten vorhanden sind, die dann auch noch ausreichend mit sinnvollen Informationen erfüllt sind.
Am Ende des Auswahlprozesses ist also zu jeder Spalte bekannt, zu welchem Merkmal welcher Entität sie gehört. Dies wird in der Tabelle 3.5 unter der Spalten ,,Entität`` und ,,Merkmal`` vermerkt. Als Entitäten haben sich Geräte und Maßnahmen heraus kristallisiert. Andere Entitäten, wie z.B. Personen, werden nicht weiter untersucht, da sie für die in dieser Arbeit untersuchten Fragestellungen nicht interessant sind.
Die für die Entität Gerät (z.B. Infusionspumpe, Fahrstuhl etc) gruppierten Merkmale sind in Tabelle 3.6 mit Anzahl der Spalten und Anteil der leeren Zellen angegeben. Für die Betrachtungseinheit Maßnahme (z.B. Störungsmeldung, Maßnahme etc) sind die entsprechenden Größen in Tabelle 3.7 angegeben.
![\begin{table}\centering\includegraphics[width=9cm]{eps/strukt_sel_1}
\end{table}](img227.png) |
![\begin{table}\centering\includegraphics[width=11cm]{eps/strukt_sel_2}
\end{table}](img228.png) |
![\begin{table}\centering\includegraphics[width=11cm]{eps/strukt_sel_3}
\end{table}](img229.png) |